��� �������� ��������� �������
����� ��������� ������, ��� ��������, �������� �������������� ���������, ����������� ���������������� ���������� ����������������� �������. ���������� ��������� ��������� ���������� - � ���� ��������� �� �������� ���� ��, ������� �������� �������� ���-�������� � �������������, � ������ ��������� ���������� ��������� ������ ���� �������, Google, Rambler � ������ ���������� �����������, ������������ �������������.
������������ ��������� ������, ����� ��� ��������� ����, ������� �� ���� ������, ���������� ����������� ���� � ������ ������:
- ���������� - �������, ����������� ��������� (HTML-�����, ��������, Flash), �������������� ������� ��� ������������, � ����������� �� �� �����, �������, ������, �������� ��� �������� � ���� ������;
- ��������� �������� - ����� ������������ �����������, ��������������� ������ � �������� ���������� � ������������ � �������� ������������.
��������� ���������� �� ����.
��� ��������� ���������� � ����� ������������ �������������� ������������ ����������, ������������ ���������� �����������, - ����� (�� ����. Spider). ����� ����������������� ��������� �������� Crawler ��� ��� (����. Bot).
������ ������ «�����» - ������ ��� ����� ������ ���������� � ���� � �������� �����, ��������� ������� ������ (���������� ����������) � ��� ������������ (�������� ����������, ���������� � ������� ����������). ������� �� ��������� � ��������� ���������� �� ������� - ���� ���� �������� ��������� �� ������, �� ������ ����������� � ������ ����������, ���������� ������.
��� �������, ��������� ������ ��������� ������������ ������ ����� �������, ������ �� ������� ��������� ���� �������, ������������ ������� ��� ������� ����������, ������� � ������� �� ������������. ���������� ���������� ���������� �� ������� �� ����� ������, ��� ��� ������ �������� �� ������� �� �������. � ���� ������ ������ ���� ���������, ������������ �� ��������� � ������ � �������������� �������� �� ������������� �������. ���� �� ���������� ��������� ������ �������� � ������ � ���� �� ������� � ����������� ���.
��� ���������� ����� ���������� ����� �� ���������� ��������� ���������� � �������, ��� � ������� ��������, - ���������� HTTP. ������� ��� ������ «������» �� �� �����, ��� � ������� ������������, �� ����������� �������� �� ���������� (��������, �������� � ������ ��������� ��������� �������). �������������� ����� � ������������ ������ ���������� ���������� ���������� (cloaking), ��������� ���������� ������ � ����� ���� �������� ����������� ��������� ����� ����������� �� ������� (����������� ����� � ��������� �����, �� �������� ������������ ����� �, ��� ���������, ����������� ����� � ����������� ������).
���� � �����-�� ������ �������� �� ����� ���� ������, �� ���� ������ ������� ������� �������� �����. ����� ���������� ���������� ���������� ������� �������� ��������� �� ���������� ����� �, ��� ���������, �� ����������� ������, ���� �� ��� ���������.
���������� ����� ���� ������������ �� ������ ���������: � ������, � �������, �� PageRank ��� ������� ������������, ������ ��� ������ �������� ����� - ������ � �������� ������� ����� ��� ��������� ��������� ����������. ������� ���������� ������� �������� ����������� (��� ��������������) ����������� �� ������ �����: ����� robots.txt (������������, ��� ��������� ���������, � ��� ���), ����-���� nofollow, noindex (�����������, ����� �� ���������� �� ������� � ������ ��������� ��� ������� ���), � ����� ����� ����������, ��� sitemaps, ������������� ������ ���������� ����� ���������� ��������.
�������� ����������
����������� ��������� � ���� ��������� ����� ��������� �� ������ ���������������� ������� - ����������� ��������� ����������� �� �����, � ����� �� ������ ������������ ������� ������������ ���� � ����������, ���������� ��� �����. ������������ �������� ���������������� ������� �������� ��������� �������� � ����� �����, ����������� �� ����� �������� (��� � ����� ��������� � �������� ��������� �������) ����������� ��������� ������. ������ � ����� ����� �������� ������� ��������, ��������, ���� �� ������� ������: � ������ ���������������� ������� �� ����� ������ �������, �� ������� ����������� �����, � ������ ������������ ��������������� ��������, � ��� ������ ������ �� ��������� ���� �� ���������� ����� ������, ��� ����� ������������.
��� ���������� ������ ����� �������� ������������� � ��������� ��� � �������������� ��������� ������� ��������� �������� ��� �������� (�� ����. parser). ����������� ������� ����������� � ���� �� ������ ��������� � html-���������. ��� �������� �� ���������� ��������, ��������, pdf, doc, swf � �.�. ������ ������ ���������� ������ ��������� � �������� ����������, �������� ��� ���������: ���������� � ����������, �������, ������������, ������������ � ������ ��������� ��������, ����������� �� � ���������� ������, � � ��� ���������. ��������� ��������� ������������ ��� ����� ���� ���� (term weight) � ��� ��� ������: �����, ������������ � ��������� ������ ���������, ����� ������� ��� ����� ���� �� �������, ������������� � ���������� ����� ����������� � ���������. � ���� ������� ����� � ���������� � ����� ��������� (�������� h1-h6 � ������ ��������� html) ����� ������� �������� ��� ������, ��� ����� �� ���������� ��� ������������ ������� � �.�. � ������������ �� ���������� ������� ����� ������������� ���.
���������, ��������� �� �����������, ������ �� ����� (������). ���� ����� ��������� ������������ �� ��������, ��������� ����� � ������ ��������, ���������� ���������� ������� ����. ������ � ��������� ������� ������� ����� �������� ���� ��� ����� ��������-�������� ������������������� - � ���� ������ ����� «CanonEos888» ����� ��������� �� ���: «Canon», «Eos» � «888». ���������� ����� ���������� � ���������������� ���� (�������������), �������� �� ������, ����� ��� ����. ����� ������� ���������� �����, ����������� � ������ ������ ����������������� � ������ � ���� �� ����. ��-������, ��� ��������� ����� ����� �������� � ���������� ������� �� ����������: ��������� ���������� ��������� ������ ���� ������ � ���� �� ����� (������� ������� � ���������) � ������� ��������, �� ����� ����� ����� ������ ���������, ��������������� (�����������) ���������� �������, �������� (��������) �� �� ������� ������������. � ��-������, ��������� ��������� ������������ ����, �� ����� ����� ����� ������ ������������ ���������� �� ��� ������, ���������� ����� �����, �������� �� ����� ����� �� ����� � ���������� ���������: ��������, � ��������� ����� ����������� �������������� «������� ������», � ���� �������� ������ ���� ������� ������������ � ������������ � �������� «������� ������».
����������, �������� (�������� �� ������) �����, ��������������� ��� ����������� �������������, ����� ��������� ���������� �������: ��������, ����������� «������ ������ �� ����, ��� ���� ����� �����» ������������� � «������ ������ ����/������ ���� ����� ���/�����», ������ ��� «����������» ��������� ������� �������� ��� �������� ���������� � ����������� ������ �� ���. ��������, ��� � ������ ������������� ���������� ����������, �� ����������� �� ��������� ������, �� ������ ������� ����� ���������� ����� ����, ��� �������� � �������������� � ��������������� ��������� �������� (�������������).
��� ������������� ��������� ���������������� ������� ��������� ��� ����������� � ����� ������� ��� ����, ����� �� ��������� ����������� ��� �����������. ��������, ���� «�» ��� ������� «��», ������������� ���������� ����� � ������ ��������� ��� ���� �����������, ������ �� � ����, ��� ������� ������������ ���� ���� � �������, ���������� �����, ��������� �� �������� ��������. ��� ����������� �� ������� �������� ������ (�������� �������� ������� � ������� ������� ����������), ����� �� ������� �� ��� �������� (����� �������� ���� ������ ����� ����������� �� ��������).
��� ���� ����� �������� �������� ��������, �� ����� �������������� �������� ����������� � ���� ����-����, ������������ ������������. ����� �� «��������» ��������� ���� ������� �������, � �������� ������ �������� ��������� �������� �����, � ����� �������� ����� ������������� ��������, ������� � ������ �����, ����� �������������� ��� ������, �� ����� �������������� � ����������. ��� ������, ���� ����-���� ����������� ���������� �� �ndex.Server �������� ����� �����, ��� «���», «�������», «�����», «���» � �.�. ��� �� ����� ���������� � �� ����������� ��� ������� � ���� ������, ��������� ��� �� �������� ���� ��� ����������.
���������� ����� ���� ������������ ����� ���������� �� ������� ������ ������ � ����. � ������� ������������ �������� �������, � ������� ����� �������� � ��������������� ������. ���������� �������� ������� � �������� ����������� ���� ���� ���� ������ ��� ����� ����, ������������ ����� ���� ��������� (��������, � ������� ����������� ����� ��������� ������� ������ ���������������). ���������, ��������� �������, ���� �� ��������� � ������, ���� ���������, �� ���������� � ����� ���������� ������.
http://www.uniplace.ru



















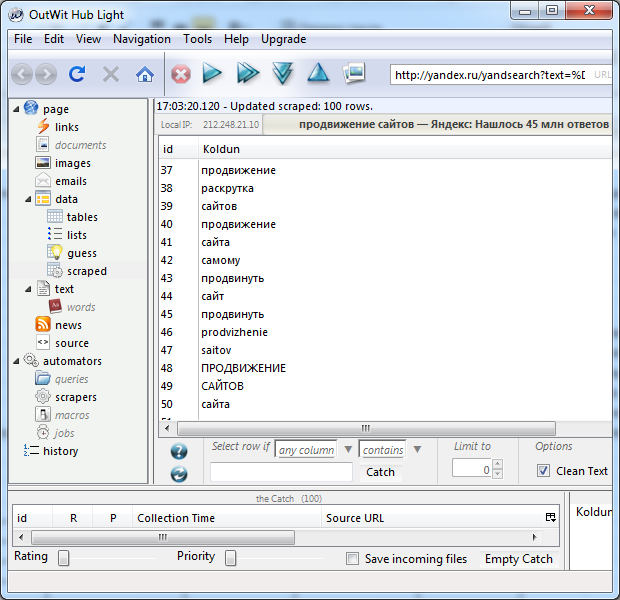
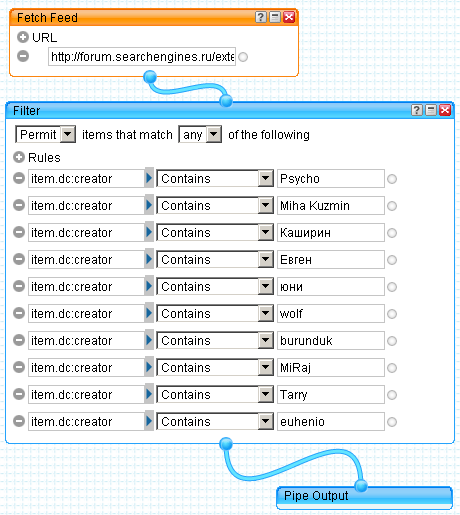
 ���� ����������� ������ � ��������� ���������� ����������� ������ ���: «������ ��� ��������»? ������� ��������: ���� ��������������� ��� ������� � ����� ���������� ������ � ��������������� ����.
���� ����������� ������ � ��������� ���������� ����������� ������ ���: «������ ��� ��������»? ������� ��������: ���� ��������������� ��� ������� � ����� ���������� ������ � ��������������� ����. �� ���������� ������ �� ����� ����� ����� ������� ����� ����������. ��� ������������� ������, ������-���������, ��������� � ������ ������ ����� ������ ���������� ������ ������� ���������� ������������� ����������� ������. ��� ������� – �������� ��������� �� �������� � ������������� ����.
�� ���������� ������ �� ����� ����� ����� ������� ����� ����������. ��� ������������� ������, ������-���������, ��������� � ������ ������ ����� ������ ���������� ������ ������� ���������� ������������� ����������� ������. ��� ������� – �������� ��������� �� �������� � ������������� ����.







 ��������, ���� ��� ����� ���� ������� �������� �������������. ����� ��������� ��, ���� ��� ��������� ���������� – � ������ � ��� �� ������� �����. � ��� � ��������� ������ ���, � �� ��������
��������, ���� ��� ����� ���� ������� �������� �������������. ����� ��������� ��, ���� ��� ��������� ���������� – � ������ � ��� �� ������� �����. � ��� � ��������� ������ ���, � �� �������� 
