|
|
|
|
[Перевод] Генерация меток для обучения модели при помощи слабого контроляСреда, 08 Июня 2022 г. 11:51 (ссылка)
 Компаниям сложно следить за всеми новостями и мнениями о них в социальных сетях; существует огромное множество потенциально релевантных постов, и их фильтрация заняла бы много времени. Новый продукт Borealis AI был создан для решения этой проблемы путём извлечения в реальном времени информации социальных сетей, распознавания тематики и добавления метки для каждого поста с обозначением его типа. Например, пост может быть помечен как «пресс-релиз», «обзор пользователя» или «шум». Такие метки позволяют пользователям находить более чистые подмножества постов в соцсетях, которые им интересны. Чтобы создать модель машинного обучения для классификации постов по таким категориям, необходимо получить высококачественные размеченные данные обучения. Иными словами, нам нужны примеры постов в социальных сетях, которые вручную размечены как пресс-релизы или обзоры пользователей, чтобы модель могла учиться тому, как распознавать новые примеры того же типа. Читать дальше → https://habr.com/ru/post/654621/?utm_source=habrahabr&utm_medium=rss&utm_campaign=654621
[Перевод] Ручное аннотирование по-прежнему незаменимо для разработки моделей глубокого обученияПонедельник, 06 Июня 2022 г. 11:34 (ссылка)
 Не подлежит сомнению, что высококачественные размеченные массивы данных играют критичную роль в разработке новых алгоритмов глубокого обучения. Однако понимание ML и глубокого обучения по-прежнему остаётся в зачаточном состоянии. Именно поэтому команды прикладного ML и исследований ML нашей компании совместно трудятся над пониманием последних исследований в сфере ML, пытаясь разобраться, как мы можем преодолеть одну из самых больших сложностей в современной разработке ИИ, как у наших клиентов, так и для отрасли в целом. Недавно наша команда исследователей провела глубокий анализ состояния данных в области компьютерного зрения. Исследовательская статья, одобренная для Human-in-the-Loop Learning Workshop на ICML 2021, показала, что высококачественная разметка по-прежнему остаётся незаменимой для разработки точных моделей глубокого обучения. Читать дальше → https://habr.com/ru/post/665384/?utm_source=habrahabr&utm_medium=rss&utm_campaign=665384
[Перевод] 20+ популярных опенсорсных датасетов для Computer VisionЧетверг, 02 Июня 2022 г. 10:41 (ссылка)
 ИИ в первую очередь развивается благодаря данным, а не коду. Это смелое заявление несколько лет назад могло показаться нелепым, но сегодня это не так. Однако, по-прежнему существует одна проблема: высокого качества данных обучения достичь иногда очень сложно. На поиск подходящего для задач компьютерного зрения массива данных могут потребоваться дни или недели. Но не стоит волноваться, в этой статье мы составили исчерпывающий список качественных массивов данных для компьютерного зрения в свободном доступе. Читать дальше → https://habr.com/ru/post/669170/?utm_source=habrahabr&utm_medium=rss&utm_campaign=669170
[Перевод] Объединение данных с датчиков и интерполяция для Autonomous VehiclesСреда, 25 Мая 2022 г. 18:55 (ссылка)
Товарищи, рассказываю о нюансах сбора и работы с данными для Autonomous Vehicles. Как правило, для создания обучающего датасета используют данные с датчиков LIDAR и камер. Но полученные данные в сыром виде очень разрознены ,и чтобы решить эту проблему, их нужно правильно объединить и интерполировать. И только после этого приступать к 3D Point Cloud разметке. Читать далееhttps://habr.com/ru/post/667842/?utm_source=habrahabr&utm_medium=rss&utm_campaign=667842
[Перевод] Если вы устраняете систематическую ошибку модели, то уже слишком поздноСреда, 27 Апреля 2022 г. 11:33 (ссылка)
 ВведениеМашинное обучение — это технологический прорыв, случающийся раз в поколение. Однако с ростом его популярности основной проблемой становятся систематические ошибки алгоритма. Если модели ML не обучаются на репрезентативных данных, у них могут развиться серьёзные систематические ошибки, оказывающие существенный вред недостаточно представленным группам и приводящие к созданию неэффективных продуктов. Мы изучили массив данных CoNLL-2003, являющийся стандартом для создания алгоритмов распознавания именованных сущностей в тексте, и выяснили, что в данных присутствует серьёзный перекос в сторону мужских имён. При помощи наших технологии мы смогли компенсировать эту систематическую ошибку:
Модель, обученная на нашем расширенном массиве данных CoNLL-2003, характеризуется снижением систематической ошибки и повышенной точностью, и это показывает, что систематическую ошибку можно устранить без каких-либо изменений в модели. Мы выложили в open source наши аннотации Named Entity Recognition для исходного массива данных CoNLL-2003, а также его улучшенную версию, скачать их можно здесь. Читать дальше → https://habr.com/ru/post/657123/?utm_source=habrahabr&utm_medium=rss&utm_campaign=657123
[Перевод] Датацентрический и моделецентрический подходы в машинном обученииВторник, 19 Апреля 2022 г. 11:31 (ссылка)
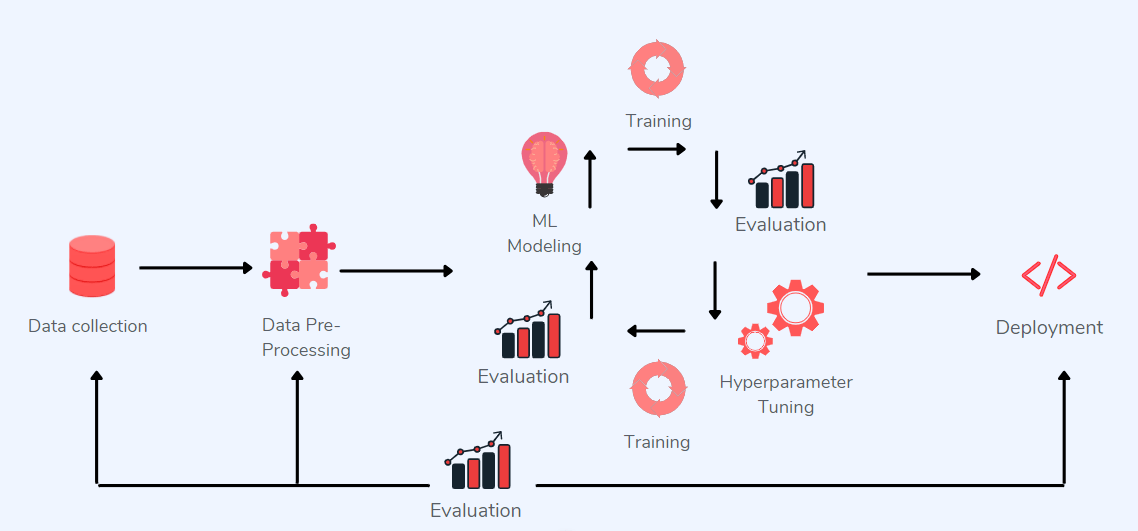 Код и данные — фундамент ИИ-системы. Оба эти компонента играют важную роль в разработке надёжной модели, но на каком из них следует сосредоточиться больше? В этой статье мы сравним методики, ставящие в центр данные, либо модель, и посмотрим, какая из них лучше; также мы поговорим о том, как внедрять датацентрическую инфраструктуру. Читать дальше → https://habr.com/ru/post/661457/?utm_source=habrahabr&utm_medium=rss&utm_campaign=661457
Разметка именованных сущностей в Label StudioПятница, 08 Апреля 2022 г. 11:34 (ссылка)
В предыдущей статье мы уже подробно рассмотрели процесс разметки семантической сегментации в CVAT. Сейчас я подробнее расскажу по NER-разметку в другом популярном open source инструменте Label Studio Предупреждаю, статья в первую очередь направлена на новичков, которые делают первые шаги в разметке данных. Как и в прошлый раз мы шаг за шагом пройдем путь от установки и настройки проекта до экспорта уже размеченного датасета. В процессе будем подробнее останавливаться на нюансах связанных с извлечением именованных сущностей и рекомендациях из личного опыта. Посмотрим, что у тебя там...https://habr.com/ru/post/659791/?utm_source=habrahabr&utm_medium=rss&utm_campaign=659791 Семантическая сегментация изображений в CVATВторник, 05 Апреля 2022 г. 19:09 (ссылка)
Товарищи, я начинаю цикл статей-туториалов по разметке данных с помощью разного ПО. Начать решил с самого знаменитого из всех бесплатных инструментов - Computer Vision Annotation Tool. Им может воспользоваться буквально любой желающий, достаточно только зарегистрироваться. Предупреждаю: это вводная статья для новичков, призванная решить самые главные вопросы "как это работает и куда тыкать". Экспертов прошу поправить или дополнить написанное. На русском языке не встречал настолько подробных гайдов. Думаю он будет очень полезен. Ну посмотрим, что там у тебя...https://habr.com/ru/post/659251/?utm_source=habrahabr&utm_medium=rss&utm_campaign=659251
|
|
|
LiveInternet.Ru |
Ссылки: на главную|почта|знакомства|одноклассники|фото|открытки|тесты|чат О проекте: помощь|контакты|разместить рекламу|версия для pda |