|
|
[Перевод] Разметка данных: бизнес на миллиарды долларов, лежащий в основе прогресса AIВторник, 10 Января 2023 г. 14:48 (ссылка)
 Когда два года назад Лэй Ван стала аннотатором данных, её работа была относительно простой: определять гендер людей на фотографиях. Но с тех пор Ван заметила, что сложность её задач становится всё выше: от разметки гендера до разметки возраста, от рамок вокруг 2D-объектов до 3D-разметки, от фотографий при дневном свете до сцен ночью и в тумане, и так далее. Ван 25 лет. Она работала секретарём в приёмной, однако когда в 2017 году её компания закрылась, друг, работавший разработчиком алгоритмов, предложил ей исследовать новый карьерный путь в аннотировании данных — процессе разметки данных, позволяющем применять их в системах искусственного интеллекта, особенно с использованием машинного обучения с учителем. Став безработной, она решила рискнуть. Два года спустя Ван уже работала помощником проект-менеджера в пекинской компании Testin. Обычно она начинает свой рабочий день со встречи с клиентами, которые в основном представляют китайские технологические компании и стартапы в сфере AI. Клиент сначала передаёт ей в качестве теста небольшую долю массива данных. Если результаты удовлетворяют требованиям, Ван получает массив данных полностью. Затем она передаёт его производственной команде, обычно состоящей из десяти разметчиков и трёх контролёров. Такие команды настроены на эффективность и могут, например, аннотировать 10 тысяч изображений для распознавания дорожных полос примерно за восемь дней с точностью в 95%. Читать дальше → https://habr.com/ru/post/706974/?utm_source=habrahabr&utm_medium=rss&utm_campaign=706974
[Перевод] Как опенсорсные инструменты замедляют разработку моделей для анализа медицинских снимковВторник, 03 Января 2023 г. 19:56 (ссылка)
 Существует множество опенсорсного ПО и инструментов для проектов компьютерного зрения и машинного обучения в сфере медицинских визуализаций. Иногда может быть выгодно использовать опенсорсные инструменты при тестировании и обучении модели ML на массивах данных медицинских снимков. Вы можете экономить деньги, а многие инструменты, например, 3DSlicer и ITK-Snap, предназначены специально для аннотирования медицинских снимков и обучения моделей ML на массивах данных из сферы здравоохранения. В здравоохранении критически важны качество массива данных и эффективность инструментов, используемых для аннотирования и обучения моделей ML. Это может стать вопросом жизни и смерти для пациентов, ведь для их диагностирования медицинским специалистам и врачам нужны максимально точные результаты моделей компьютерного зрения и машинного обучения. Как известно командам клиницистов и обработки данных, слои данных в медицинских снимках сложны и детализированы. Для выполнения работы вам нужны подходящие инструменты. Применение неверного инструмента, например, опенсорсного приложения для аннотирования, может негативно повлиять на разработку модели. В этой статье мы расскажем об основных опенсорсных инструментах для аннотирования медицинских снимков, сценариях применения таких инструментов и о том, как они препятствуют развитию вашего проекта. Мы перечислим те возможности инструмента аннотирования, которые помогут вам преодолеть эти трудности, в том числе и функции, которые обеспечат нужные вам результаты. Читать дальше → https://habr.com/ru/post/707874/?utm_source=habrahabr&utm_medium=rss&utm_campaign=707874
[Перевод] Шесть шагов для создания более качественных моделей Computer VisionВоскресенье, 26 Декабря 2022 г. 00:25 (ссылка)
 Компьютерное зрение (computer vision, CV) — подраздел искусственного интеллекта, использующий алгоритмы машинного обучения и глубокого обучения для распознавания и интерпретации объектов на изображениях и видео. CV сосредоточено на воссоздании аспектов сложности зрительной системы человека, позволяя компьютерам определять и анализировать предметы на фотографиях и видео точно так же, как это делают люди. За последние годы в области компьютерного зрения произошёл существенный прогресс, благодаря прорывам в искусственном интеллекте и инновациям в глубоком обучении и нейронных сетях компьютеры превзошли людей в различных задачах, связанных с распознаванием объектов. Одним из движущих факторов эволюции компьютерного зрения является объём генерируемых сегодня данных, которые применяются для обучения и совершенствования CV. В этой статье мы сначала рассмотрим способы применения моделей компьютерного зрения в реальном мире, чтобы понять, почему нам нужно создавать более качественные модели. Затем мы перечислим шесть способов совершенствования моделей компьютерного зрения при помощи улучшения обработки данных. Но для начала давайте вкратце обсудим различия между моделями компьютерного зрения и машинного обучения. Читать дальше → https://habr.com/ru/post/705008/?utm_source=habrahabr&utm_medium=rss&utm_campaign=705008
Кейсы разметки в CVAT #1: найди отличияСреда, 07 Декабря 2022 г. 22:18 (ссылка)
Привет, дорогие читатели! Меня зовут Алина, я работаю операционным менеджером в компании Training Data, которая занимается сбором и разметкой данных. Я веду проекты по разметке, а еще благодаря знанию python пишу скрипты для автоматизации работы своей команды. У меня накопилось много интересного опыта, которым я хочу с вами поделиться. Своей первой статьей я открываю рубрику разбора любопытных кейсов, с которыми столкнулись я и мои коллеги во время организации разметки данных в CVAT. “Computer Vision Annotation Tool (CVAT) – это инструмент с открытым исходным кодом для разметки цифровых изображений и видео. Основной его задачей является предоставление пользователю удобных и эффективных средств разметки наборов данных. “ - цитата из статьи создателей. Все мы с вами прекрасно знаем детскую игру на развитие внимательности и наблюдательности - поиск отличий на картинках. Она встречалась нам в журналах, на календарях, а позже - на сайтах и мемах в VK. Но кто бы мог подумать, что подобная забава дойдет и до разметки данных для обучения нейронных сетей? Читать дальшеhttps://habr.com/ru/post/704160/?utm_source=habrahabr&utm_medium=rss&utm_campaign=704160
[Перевод] 10 лучших опенсорсных инструментов аннотирования для компьютерного зренияПонедельник, 05 Декабря 2022 г. 17:58 (ссылка)
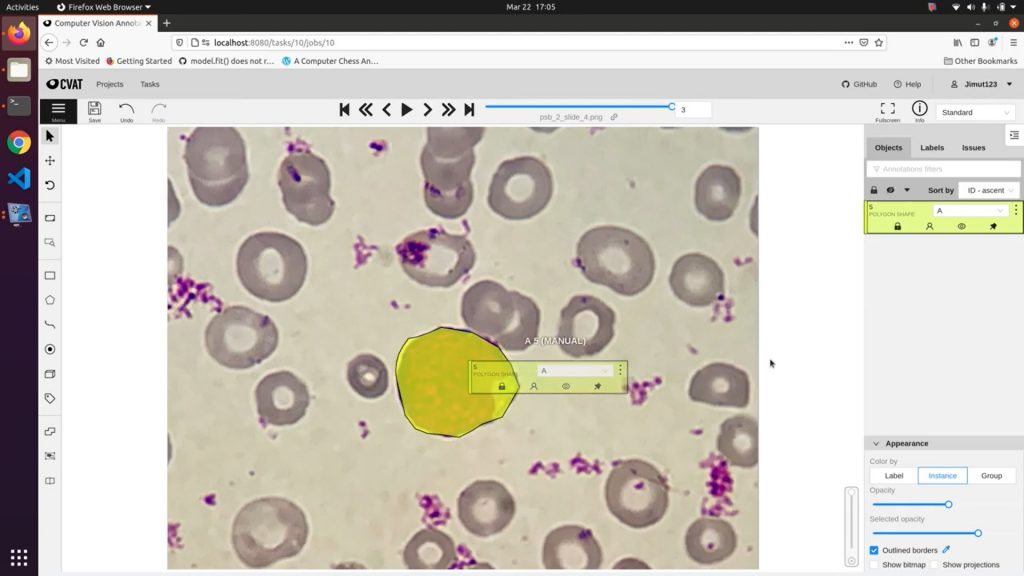 Наша компания знает важность подбора качественных инструментов разметки и аннотирования изображений для создания точных и полезных массивов данных. В нашем блоге можно найти серию статей Tools we love, в которой мы подробно рассматриваем некоторые из наших любимых инструментов аннотирования, а также выбранные нами лучшие инструменты аннотирования за 2019, 2020 и 2021 годы. В процесса роста сферы аннотирования изображений мы наблюдаем увеличение количества опенсорсных инструментов, позволяющих любому размечать изображения бесплатно и пользоваться широким набором функций. В этой статье мы расскажем о десяти лучших опенсорсных инструментах аннотирования для машинного зрения! Читать дальше → https://habr.com/ru/post/703208/?utm_source=habrahabr&utm_medium=rss&utm_campaign=703208
[Перевод] Большой объём данных для машинного обучения — не панацеяВторник, 09 Ноября 2022 г. 02:21 (ссылка)
 Модели глубокого обучения обладают потрясающим свойством — они становятся лучше с увеличением объёма данных, и кажется, что этот процесс практически неограничен. Чтобы получить качественно работающую модель, недостаточно больших объёмов данных, нужны ещё и точные аннотации. Хотя большие объёмы данных помогают модели решать проблему несогласованности данных в разных аннотациях, люди всё равно могут совершать повторные ошибки, укореняющиеся в модели. Например, когда человеку нужно нарисовать вокруг объекта прямоугольник, он обычно стремится, чтобы объект точно попал в этот прямоугольник, то есть склонен ошибаться в сторону увеличения прямоугольника. Использование такой модели для избегания столкновений приведёт к ложноположительным результатам, из-за чего беспилотный транспорт будет останавливаться без причины. Превышение размера ограничивающих прямоугольников — пример систематической ошибки, а бывают ещё и случайные. Случайные и систематические ошибки влияют на обученную модель по-разному. Читать дальше → https://habr.com/ru/post/695548/?utm_source=habrahabr&utm_medium=rss&utm_campaign=695548
[Перевод] Подготовка датасета для машинного обучения: 10 базовых способов совершенствования данныхПонедельник, 19 Сентября 2022 г. 11:34 (ссылка)
 У Колумбийского университета есть хорошая история о плохих данных. Проект в сфере здравоохранения был нацелен на снижение затрат на лечение пациентов с пневмонией. В нём использовалось машинное обучение (machine learning, ML) для автоматической сортировки записей пациентов, чтобы выбрать тех, у кого опасность смертельного исхода минимальна (они могут принимать антибиотики дома), и тех, у кого опасность смертельного исхода высока (их нужно лечить в больнице). Команда разработчиков использовала исторические данные из клиник, а алгоритм был точным. Но за одним важным исключением. Одним из наиболее опасных состояний при пневмонии является астма, поэтому врачи всегда отправляют астматиков в отделение интенсивной терапии, что приводило к минимизации уровня смертности для этих пациентов. Благодаря отсутствию смертельных случаев у астматиков в данных алгоритм предположил, что астма не так уж опасна при пневмонии, и во всех случаях машина рекомендовала отправлять астматиков домой, несмотря на то, что для них риск осложнений при пневмонии был наибольшим. ML сильно зависит от данных. Это самый критически важный аспект, благодаря которому и возможно обучение алгоритма; именно поэтому машинное обучение стало столь популярным в последние годы. Но вне зависимости от терабайтов информации и экспертизы в data science, если ты не можешь понять смысл записей данных, то машина будет практически бесполезной, а иногда и наносить вред. Читать дальше → https://habr.com/ru/post/684580/?utm_source=habrahabr&utm_medium=rss&utm_campaign=684580
Изучение нейросетевого подхода к решению OCR на примере задачи распознавания арабского текстаПятница, 12 Августа 2022 г. 18:22 (ссылка)
Оптическое распознавание символов (Optical Character Recognition) — одна из первых задач компьютерного зрения, заключается в переводе изображений рукописного или печатного текста в текстовые данные, использующиеся в компьютере. Поэтому в этой статье мы будем изучать и тестировать подходы, основанные именно на этой технологии. Далее мы рассмотрим различные подходы к решению задач OCR и сравним их, а также попробуем разобраться, как подобрать подходящий инструмент для конкретной проблемы. Для эксперимента мы выбрали нестандартную задачу - распознавание арабского текста. Читать далееhttps://habr.com/ru/post/682270/?utm_source=habrahabr&utm_medium=rss&utm_campaign=682270
[Перевод] Как за неделю разметить миллион примеров данныхПятница, 12 Августа 2022 г. 12:51 (ссылка)
 В 2019 году компания OpenAI опубликовала статью о точной настройке GPT-2, в которой она использовала Scale AI для сбора мнений живых разметчиков с целью совершенствования своих языковых моделей. Хотя в то время мы уже размечали миллионы задач обработки текста и computer vision, уникальные требованиях к срокам и субъективная природа задач OpenAI создали для нас новую сложность. В частности, трудность заключалась в следующем: как поддерживать качество меток в больших масштабах без возможности проверки чужой работы разметчиками? Сегодня мы подробно расскажем о своём подходе к решению этой проблемы, о системе автоматического майнинга бенчмарков, которую мы для этого создали, а также об уроках, которые получили в процессе. Этой статьёй мы хотим проиллюстрировать небольшую часть тех сложностей, делающих масштабируемую разметку данных такой интересной сферой работы. Читать дальше → https://habr.com/ru/post/680960/?utm_source=habrahabr&utm_medium=rss&utm_campaign=680960
О важности датасета и о том, как сделать его лучше. Опыт нашей компанииПонедельник, 25 Июля 2022 г. 12:46 (ссылка)
Краеугольный камень любого проекта, связанного с компьютерным зрением - датасет. Это не просто набор изображений, который передается нейросети. Датасет - это базовый блок, который определит качество и точность определения объектов в рамках вашего проекта. Нельзя просто собрать набор изображений из гугла и успокоиться - полученная куча изображений не будет нести гордое название «датасет» и испортит проект, вынуждая разработчика и компьютерное железо тренировать модель снова и снова. Мы подготовили 7 основных шагов, которые превратят набор картинок из гугла не просто в мощный базовый блок системы компьютерного зрения, но и основной инструмент по выявлению и устранению ошибок распознавания. Читать далееhttps://habr.com/ru/post/678808/?utm_source=habrahabr&utm_medium=rss&utm_campaign=678808
[Перевод] Разметка данных в машинном обучении: процесс, разновидности и рекомендацииПонедельник, 25 Июля 2022 г. 11:04 (ссылка)
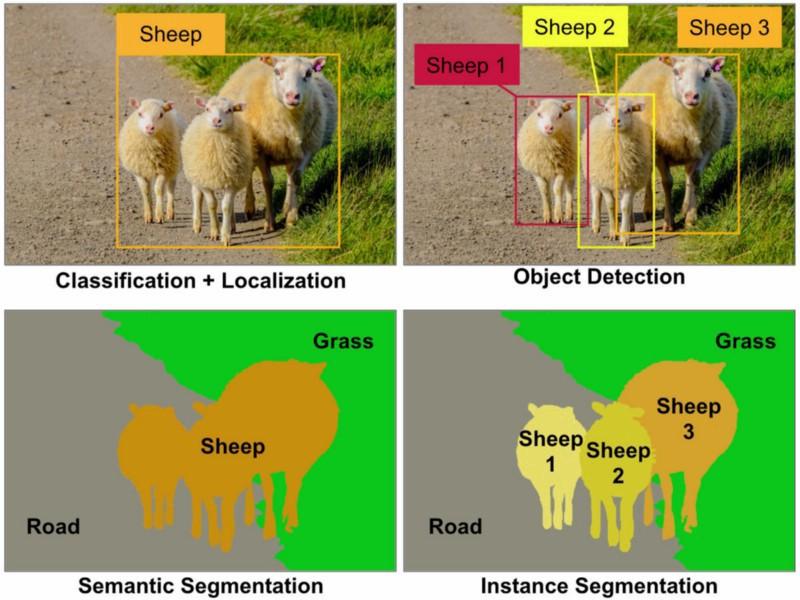 Когда люди слышат про искусственный интеллект, глубокое обучение и машинное обучение, многие представляют роботов из фильмов, интеллект которых сравним или даже превосходит интеллект человека. Другие считают, что такие машины просто потребляют информацию и учатся на ней самостоятельно. Но на самом деле это далеко от истины: без человеческой помощи возможности компьютерных систем ограничены, и чтобы они стали «умными», необходима разметка данных. В этой статье мы расскажем, что такое разметка данных, как она работает, о типах разметки данных и о рекомендациях, позволяющих сделать этот процесс беспроблемным. Читать дальше → https://habr.com/ru/post/678524/?utm_source=habrahabr&utm_medium=rss&utm_campaign=678524
[Перевод] Опенсорсные массивы данных для Computer VisionСреда, 06 Июля 2022 г. 12:18 (ссылка)
 Модели Computer Vision, обучаемые на опенсорсных массивах данныхComputer Vision (CV) — одна из самых увлекательных тем в сфере искусственного интеллекта (Artificial Intelligence, AI) и машинного обучения (Machine Learning, ML). Это важная часть многих современных конвейеров AI/ML, преобразующая практически все отрасли и позволяющая компаниям осуществлять революцию в работе машин и бизнес-систем. В науке CV многие десятилетия была уважаемой областью computer science, и за многие годы в этой сфере было проведено множество исследований по её совершенствованию. Однако революцию в ней совершило недавно начавшееся применение глубоких нейросетей, ставшее стимулом ускорения её развития. Читать дальше → https://habr.com/ru/post/669886/?utm_source=habrahabr&utm_medium=rss&utm_campaign=669886
[Перевод] Как мы масштабируем машинное обучениеПонедельник, 13 Июня 2022 г. 12:11 (ссылка)
 ВведениеНаша компания еженедельно размечает порядка 10 миллиардов аннотаций. Чтобы обеспечивать высокое качество аннотаций для такого огромного объёма данных, мы разработали множество методик, в том числе sensor fusion для выявления подробностей о сложных окружениях, активный инструментарий для ускорения процесса разметки и автоматизированные бенчмарки для измерения и поддержания качества работы разметчиков. С расширением количества заказчиков, разметчиков и объёмов данных мы продолжаем совершенствовать эти методики, чтобы повышать качество, эффективность и масштабируемость разметки. Как мы используем MLОбширные объёмы передаваемых компании данных предоставляют ей бесценные возможности обучения и надстройки наших процессов аннотирования, и в то же время позволяют нашей команде разработчиков машинного обучения обучать модели, расширяющие набор доступных нам функций. Читать дальше → https://habr.com/ru/post/659069/?utm_source=habrahabr&utm_medium=rss&utm_campaign=659069
Как быстро создать обучающий датасет для задач обнаружения объектов YOLO с помощью Label StudioЧетверг, 09 Июня 2022 г. 12:44 (ссылка)
Обнаружение объектов — одна из подзадач компьютерного зрения для идентификации определенных объектов. Например, люди, здания, растений, дорожных знаков или транспортные средства на изображениях и видео. Для создания таких моделей существует множество различных типов алгоритмов, таких, как Scale-invariant feature transform (SIFT), Detectron, RefineDet или You Only Look Once (YOLO). Их часто используют в самых разных отраслях, начиная с автономного вождения и охранных систем, заканчивая автоматизацией на производстве и распознаванием лиц. Как и с любой моделью машинного обучения, всё начинается с создания обучающего набора данных. Сделать это можно разными способами: можно заказать разметку данных, а можно всё сделать самому. Конечно, второй вариант займет намного больше времени и сил, но с помощью правильно подобранного ПО можно неплохо упростить задачу. Сейчас я подробно расскажут, как быстро создать обучающий датасет для задач детекции объектов YOLO с помощью Label Studio. Посмотрим, что у тебя там...https://habr.com/ru/post/670532/?utm_source=habrahabr&utm_medium=rss&utm_campaign=670532
[Перевод] Генерация меток для обучения модели при помощи слабого контроляСреда, 08 Июня 2022 г. 11:51 (ссылка)
 Компаниям сложно следить за всеми новостями и мнениями о них в социальных сетях; существует огромное множество потенциально релевантных постов, и их фильтрация заняла бы много времени. Новый продукт Borealis AI был создан для решения этой проблемы путём извлечения в реальном времени информации социальных сетей, распознавания тематики и добавления метки для каждого поста с обозначением его типа. Например, пост может быть помечен как «пресс-релиз», «обзор пользователя» или «шум». Такие метки позволяют пользователям находить более чистые подмножества постов в соцсетях, которые им интересны. Чтобы создать модель машинного обучения для классификации постов по таким категориям, необходимо получить высококачественные размеченные данные обучения. Иными словами, нам нужны примеры постов в социальных сетях, которые вручную размечены как пресс-релизы или обзоры пользователей, чтобы модель могла учиться тому, как распознавать новые примеры того же типа. Читать дальше → https://habr.com/ru/post/654621/?utm_source=habrahabr&utm_medium=rss&utm_campaign=654621
[Перевод] Ручное аннотирование по-прежнему незаменимо для разработки моделей глубокого обученияПонедельник, 06 Июня 2022 г. 11:34 (ссылка)
 Не подлежит сомнению, что высококачественные размеченные массивы данных играют критичную роль в разработке новых алгоритмов глубокого обучения. Однако понимание ML и глубокого обучения по-прежнему остаётся в зачаточном состоянии. Именно поэтому команды прикладного ML и исследований ML нашей компании совместно трудятся над пониманием последних исследований в сфере ML, пытаясь разобраться, как мы можем преодолеть одну из самых больших сложностей в современной разработке ИИ, как у наших клиентов, так и для отрасли в целом. Недавно наша команда исследователей провела глубокий анализ состояния данных в области компьютерного зрения. Исследовательская статья, одобренная для Human-in-the-Loop Learning Workshop на ICML 2021, показала, что высококачественная разметка по-прежнему остаётся незаменимой для разработки точных моделей глубокого обучения. Читать дальше → https://habr.com/ru/post/665384/?utm_source=habrahabr&utm_medium=rss&utm_campaign=665384
|
|
|
LiveInternet.Ru |
Ссылки: на главную|почта|знакомства|одноклассники|фото|открытки|тесты|чат О проекте: помощь|контакты|разместить рекламу|версия для pda |