|
|
|
|
MedBench: NLP-задачи в медицине, модели и методы их решенияЧетверг, 19 Января 2023 г. 22:55 (ссылка)
Привет, Хабр! Меня зовут Даниил Погуляка. Я студент четвертого курса МГТУ им. Н.Э. Баумана, факультета "Информатика, искусственный интеллект и системы управления". Уже некоторое время я занимаюсь изучением методов машинного обучения, в частности, касающихся автоматической обработки текстов (Natural Language Processing, NLP). В конце прошлого года мне удалось попасть на стажировку в Sber AI Lab. Оказавшись в команде проекта MedBench, у меня появилась возможность поработать над практическими NLP задачами. В этой статье я бы хотел рассказать вам о проекте, которым занимался на протяжении своей стажировки. Проект связан с использованием нейронных сетей в сфере медицины, но подробнее о нём после небольшого введения. Читать далееhttps://habr.com/ru/post/711700/?utm_source=habrahabr&utm_medium=rss&utm_campaign=711700
Лучший формат данных, для хранения pandas.DataFrameПонедельник, 16 Января 2023 г. 12:01 (ссылка)
Привет, Хабр! Меня зовут Вадим Москаленко и я разработчик инновационных технологий Страхового Дома ВСК. В этой статье, хочу поделится с вами, информацией в области хранения данных. На сегодняшний день существует огромное количество форматов для хранения данных, и, используя библиотеку Pandas при обработке большого объёма данных, возникает вопрос – а какой формат, с которыми Pandas работает «из коробки», даст наибольшую производительность, при дальнейшем использовании, обработанного DataFrame? Ремарка: поиск информации по этой теме, привёл меня к репозиторию, за авторством Devforfu (ссылка), но так как информация в нём датируется 2019 годом, а за этот период вышло множество обновлений, я решил написать «свежий» бенчмарк, основываясь на принципах автора – ссылка на обновленный бенчмарк. Отмечу, что из-за слишком большой разницы в полученных результатах, я склоняюсь к тому, что мог совершить ошибку, поэтому далее в статье будет указана информация по оригиналу. В качестве тестируемых форматов использовались следующие варианты: CSV (как самый популярный текстовый формат), Pickle, Feather, Parquet, Msgpack, HDF. Для сравнения будем использовать следующие метрики: размер сериализованного файла, время загрузки DataFrame из файла, время сохранения DataFrame в файл, потребление оперативной памяти при сохранении и загрузке DataFrame. Тестовые данные – сгенерированный DataFrame с 1 миллионом строк, 15 столбцами цифр и 15 столбцами строковых значений. Генерация численных данных проводилась с помощью numpy. random.normal, в качестве строчных данных использовались UUID. С появлением в Pandas, категориального типа данных (Categorical data), который использует гораздо меньше памяти и более производительней в обработке (обширный материал для другой статьи), интересно также сравнить насколько изменится производительность форматов, поэтому ещё одним этапом сравнения в тестовых данных стал перевод формата «object» к формату «category». Читать далееhttps://habr.com/ru/post/710798/?utm_source=habrahabr&utm_medium=rss&utm_campaign=710798
Удобный бенчмаркинг с Jetpack Benchmark Library. Макро- и микробенчмаркиСреда, 05 Октября 2022 г. 14:41 (ссылка)
Что за зверь такой этот бенчмаркинг Android-приложений? Разберемся с тем, для чего он нужен, погрузимся в детали работы Jetpack Benchmark Library и получим знания для написания первого бенчмарк-теста. Помогать в этом деле буду я, Диана Федотова, Android-разработчица из Технократии. Узнать про бенчмаркингhttps://habr.com/ru/post/691620/?utm_source=habrahabr&utm_medium=rss&utm_campaign=691620
[Перевод] Знакомимся с дата-ориентированным проектированием на примере RustПятница, 19 Августа 2022 г. 10:53 (ссылка)
James McMurrayВ этом посте мы исследуем основные концепции «Data-Oriented Design» (далее «дата-ориентированное проектирование» на языке Rust. Весь исходный код для этого поста выложен на Github. Читать дальше → https://habr.com/ru/post/683386/?utm_source=habrahabr&utm_medium=rss&utm_campaign=683386
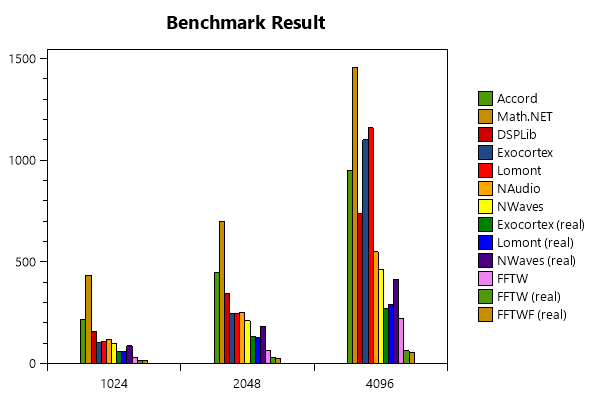
[Перевод] Сравнение реализаций БПФ для .NETПятница, 08 Июля 2022 г. 16:00 (ссылка)
https://habr.com/ru/post/675438/?utm_source=habrahabr&utm_medium=rss&utm_campaign=675438
Рейтинг русскоязычных энкодеров предложенийВоскресенье, 05 Июня 2022 г. 22:18 (ссылка)
Энкодер предложений (sentence encoder) – это модель, которая сопоставляет коротким текстам векторы в многомерном пространстве, причём так, что у текстов, похожих по смыслу, и векторы тоже похожи. Обычно для этой цели используются нейросети, а полученные векторы называются эмбеддингами. Они полезны для кучи задач, например, few-shot классификации текстов, семантического поиска, или оценки качества перефразирования. Но некоторые из таких полезных моделей занимают очень много памяти или работают медленно, особенно на обычных CPU. Можно ли выбрать наилучший энкодер предложений с учётом качества, быстродействия, и памяти? Я сравнил 25 энкодеров на 10 задачах и составил их рейтинг. Самой качественной моделью оказался mUSE, самой быстрой из предобученных – FastText, а по балансу скорости и качества победил rubert-tiny2. Код бенчмарка выложен в репозитории encodechka, а подробности – под катом. Читать далееhttps://habr.com/ru/post/669674/?utm_source=habrahabr&utm_medium=rss&utm_campaign=669674
NVIDIA А5500: реальная мощь или фейслифтинг?Среда, 26 Мая 2022 г. 02:24 (ссылка)
Проверили новую GPU NVIDIA RTX A5500 на архитектуре Ampere с RT-ядрами второго поколения и тензорными — третьего. Хороша ли новинка? Для чего использовать — энкодинг, майнинг, нейросети? Рассказываем о результатах теста. Узнать подробностиhttps://habr.com/ru/post/667886/?utm_source=habrahabr&utm_medium=rss&utm_campaign=667886
|
|
|
LiveInternet.Ru |
Ссылки: на главную|почта|знакомства|одноклассники|фото|открытки|тесты|чат О проекте: помощь|контакты|разместить рекламу|версия для pda |