|
|
|
|
Тенденции интернет-маркетинга в 2024 году от HICLICKПятница, 17 Ноября 2023 г. 15:15 (ссылка)
Теория вероятностей в машинном обучении. Часть 2: модель классификацииПятница, 03 Февраля 2023 г. 14:19 (ссылка)
В предыдущей части мы рассматривали вероятностную постановку задачи машинного обучения, статистические модели, модель регрессии как частный случай и ее обучение методом максимизации правдоподобия. В данной части рассмотрим метод максимизации правдоподобия в классификации: в чем роль кроссэнтропии, функций сигмоиды и softmax, как кроссэнтропия связана с "расстоянием" между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии. Данная часть содержит много отсылок к формулам и понятиям, введенным в первой части, поэтому рекомендуется читать их последовательно. В третьей части (статья планируется) перейдем от метода максимизации правдоподобия к байесовскому выводу и его различным приближениям. Данная серия статей не является введением в машинное обучение и предполагает знакомство читателя с основными понятиями. Задача статей - рассмотреть машинное обучение с точки зрения теории вероятностей, что позволит по новому взглянуть на проблему, понять связь машинного обучения со статистикой и лучше понимать формулы из научных статей. Также на описанном материале строятся более сложные темы, такие как вариационные автокодировщики (Kingma and Welling, 2013), нейробайесовские методы (M"uller et al., 2021) и даже некоторые теории сознания (Friston et al., 2022). Читать далееhttps://habr.com/ru/post/714670/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714670
[Перевод] Революция генеративного ИИ началась — как мы к этому пришли?Пятница, 03 Февраля 2023 г. 11:09 (ссылка)
Сегодня только и разговоров, что о ChatGPT, Midjourney и прочих DALL-E. Почему именно сейчас нейросети стали такими крутыми и развиваются семимильными шагами? Прорыв стал возможен благодаря новому классу невероятно мощных моделей искусственного интеллекта. Рассказываем, с чего всё началось и как мы здесь оказались. Читать далееhttps://habr.com/ru/post/714588/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714588
[Перевод] Представление, кластеризация и подобие в примерах, иллюстрациях и таблицахЧетверг, 02 Февраля 2023 г. 21:52 (ссылка)
Ключевые элементы машинного обучения и скрытых пространств
Эта статья послужит введением в представление (embedding), подобие (similarity) и кластеризацию (clustering). Знать эти ключевые понятия машинного обучения нужно, чтобы понять, что такое скрытое пространство.
За подробностями приглашаем под кат. Читать дальше →https://habr.com/ru/post/714304/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714304
Как мы используем нейросети для создания рекламных материаловЧетверг, 02 Февраля 2023 г. 16:17 (ссылка)
Привет! Меня зовут Роман Максимов, я руководитель группы дизайна в Омни СМ. Наша группа входит в отдел цифрового дизайна и занимается диджитал- и веб-дизайном интернет-магазина «Спортмастер» и сайтов монобрендов. Если совсем коротко, то мы отвечаем за всё, что связано с визуальной и креативной составляющей — баннеры, дизайн заглавных страниц, лендингов, видео и всю графическую маркетинговую составляющую. В этом посте я расскажу про то, как мы используем возможности нейронных сетей, чтобы создавать рекламные материалы и не только. Итак, про нейронки. Тема уже в целом не новая, но с каждым витком развития получает неплохой импульс в плане актуальности. Крупные компании стали объединять усилия в области генеративного дизайна — Shutterstock запартнёрились с DALL-E, и в будущем можно будет не тратить кучу времени, копаясь в огромном каталоге картинок, а просто взять и написать в поисковой строке нужный запрос. Сеть его обработает и нарисует для подходящую картинку. Если не очень подходящую — просто уточни запрос. Читать далееhttps://habr.com/ru/post/714474/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714474
MIDV-2020: как мы создали крупнейший датасет документов, удостоверяющих личностьЧетверг, 02 Февраля 2023 г. 13:45 (ссылка)
В этой статье мы хотим рассказать как мы создали крупнейший на данный момент набор искусственно созданных документов с большим разнообразием типов документов, их содержания и условий съемки. Каждый из документов имеет уникальные (хоть и выдуманные) значения текстовых полей, уникальную подпись и уникальные искусственно созданные лица. Читать далееhttps://habr.com/ru/post/714250/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714250
Интерпретируемость в медицинеЧетверг, 02 Февраля 2023 г. 10:24 (ссылка)
Так совпало, что я недавно прочёл статью Transparency of deep neural networks for medical image analysis и пост от канала Reliable ML про интерпретируемость. Я работаю в сфере медицины уже почти пять лет, и всё это время постоянно где-то на орбите внимания мелькает эта тема. Что такое интерпретируемость, если решается задача классификации всего рентгенологического исследования - в целом понятно. Врачи не доверяют системам, которые просто говорят "тут где-то на картинке есть рак", а значит нужны какие-то методы, которые будут "объяснять" итоговое предсказание. Их придумано довольно много - разнообразные виды GradCAMа, окклюзия, LIME. Из коробки многие из них можно взять из библиотеки Captum для Pytorch. Если вы хотите узнать ещё больше об организации процессов ML-разработки, подписывайтесь на наш Телеграм-канал Варим ML Читать далееhttps://habr.com/ru/post/714354/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714354
Мнение: Почему ChatGPT не заменит поисковикиСреда, 01 Февраля 2023 г. 20:44 (ссылка)
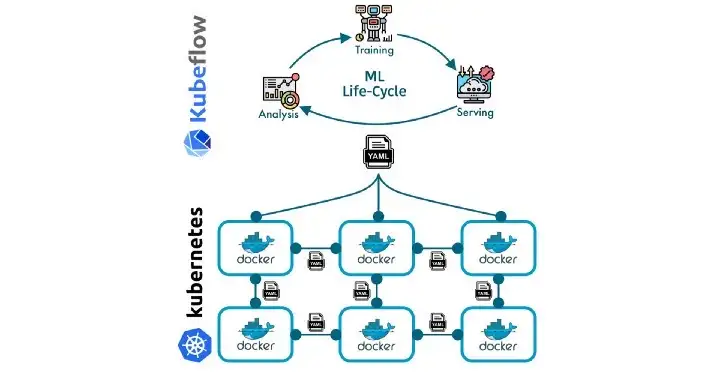
Скорее всего поисковикам не стоит бояться ChatGPT С ТЕХ ПОР, КАК OPENAI ПРЕДСТАВИЛ миру ChatGPT в ноябре прошлого года, люди используют его для создания кода, написания стихов, создания обсуждений. Теперь многие предполагают, что люди могут принять ботов в стиле ChatGPT в качестве альтернативы традиционному поиску в Интернете. Microsoft, инвестировавшая в OpenAI миллиард долларов ,планирует выпустить реализацию своей поисковой системы Bing, включающую ChatGPT, до конца марта. Согласно недавней статье в New York Times , Google объявил «красный код» из-за опасений, что ChatGPT может представлять серьезную угрозу для его поискового бизнеса с оборотом в 149 миллиардов долларов в год. Действительно ли ChatGPT может разрушить такого мастодонта поисковых систем, как Google? ChatGPT хорош в том, что он — генерирует, — но поисковой системой это не является. Есть некоторый смысл в том, что Google мог бы рассматривать чат, если бы он получил широкое распространение в качестве инструмента поиска, как угрозу своей бизнес-модели. Если меньше людей будет заниматься обычным поиском, это потенциально может оказать серьезное влияние на прибыль Google. Но реальный вопрос здесь заключается в следующем: можно ли вообще использовать ChatGPT для поиска, подобного Google? Читать далееhttps://habr.com/ru/post/714284/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714284 [Перевод] Kubeflow: учимся устанавливать и запускать Kubeflow на локальной машинеСреда, 01 Февраля 2023 г. 17:01 (ссылка)
Пошаговое руководство по установке и конфигурированию всех компонентов kubeflow на локальной машине. https://habr.com/ru/post/714172/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714172
[Перевод] Обучите YOLOv8 на пользовательском наборе данныхСреда, 01 Февраля 2023 г. 16:30 (ссылка)
Ultralytics недавно выпустила семейство моделей обнаружения объектов YOLOv8. Эти модели превосходят предыдущие версии моделей YOLO как по скорости, так и по точности в наборе данных COCO. Но как насчет производительности на пользовательских наборах данных? Чтобы ответить на этот вопрос, мы будем обучать модели YOLOv8 на пользовательском наборе данных. В частности, мы будем обучать его на крупномасштабном наборе данных для обнаружения выбоин. Читать далееhttps://habr.com/ru/post/714232/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714232
Folium. Как сделать несколько choropleth карт в одной и зачем нужна dualMap?Среда, 01 Февраля 2023 г. 14:14 (ссылка)
Привет, Хабр! Меня зовут Екатерина Кононова, я Data Scientist и участник профессионального сообщества NTA. Часто возникает проблема визуализации данных за несколько периодов времени. Те, кто уже пытался создавать карты знают, что эту проблему можно решить с помощью разных слоёв на карте. Если заглянуть в код, то можно увидеть, что именно строка folium.LayerControl(). add_to(m) позволяет добавить на карту возможность переключения между слоями, но об этом чуть позже. Читать далееhttps://habr.com/ru/post/714182/?utm_source=habrahabr&utm_medium=rss&utm_campaign=714182
Как Маруся отвечает на вопросы пользователей обо всём на светеСреда, 01 Февраля 2023 г. 11:04 (ссылка)
Привет, это команда ответов на вопросы Маруси. Мы все привыкли к тому, что голосовые помощники отвечают на любые вопросы. Не всегда правильно, но обычно вполне толково и с пользой. А вы когда-нибудь задумывались, как это устроено? Сейчас расскажем на примере нашей Маруси. Материал состоит из двух частей, это первая часть. В ней мы дадим поверхностный обзор того как устроена Маруся, локализуем место навыка «ответов на вопросы» и расскажем на концептуальном уровне, как можно решать эту задачу. Читать далееhttps://habr.com/ru/post/713124/?utm_source=habrahabr&utm_medium=rss&utm_campaign=713124
Как Маруся отвечает на вопросы пользователей обо всём на светеСреда, 01 Февраля 2023 г. 11:04 (ссылка)
Привет, это команда ответов на вопросы Маруси. Мы все привыкли к тому, что голосовые помощники отвечают на любые вопросы. Не всегда правильно, но обычно вполне толково и с пользой. А вы когда-нибудь задумывались, как это устроено? Сейчас расскажем на примере нашей Маруси. Материал состоит из двух частей, это первая часть. В ней мы дадим поверхностный обзор того как устроена Маруся, локализуем место навыка «ответов на вопросы» и расскажем на концептуальном уровне, как можно решать эту задачу. Читать далееhttps://habr.com/ru/post/713124/?utm_source=habrahabr&utm_medium=rss&utm_campaign=713124
Мониторинг аномальной активности в операционной системе «Нейтрино»Вторник, 31 Января 2023 г. 12:24 (ссылка)
Активности в операционной системе могут быть самыми разнообразными. Это может быть и запуск нового процесса или потока, и обращение к файловой системе, и выделение памяти, и многое другое. Могут возникнуть ситуации, когда (вследствие действий злоумышленника и\или программной\аппаратной ошибки) эта активность становится аномальной, то есть поведение системы начинает отличаться от ожидаемого. Запуск неизвестного процесса на этапе эксплуатации изделия, потребление процессом необычно большого количества памяти, установка сетевых соединений, которых быть не должно в системе - всё это примеры аномальной активности, возможно требующие внимания со стороны пользователя или разработчика. О процессе разработки, используемых методах и технологиях рассказываем в данной статье. Читать далееhttps://habr.com/ru/post/713690/?utm_source=habrahabr&utm_medium=rss&utm_campaign=713690 Теоретические соображения о сжатии изображений при помощи нейросетейПонедельник, 31 Января 2023 г. 00:34 (ссылка)
Взяться за статью меня побудил недавний (в исторических масштабах) эксперимент по сжатию изображений при помощи Stable Diffusion. Бегло прочесав азбучные истины вроде Википедии, я обнаружил, что проблема «красивой, но полностью выдуманной картинки» уже известна, но самое очевидное решение из приходящих в голову — по какой-то причине не фигурирует в них. Причины, которые я могу предположить — оно или уже давно отброшено как неэффективное (слишком снижающее степень сжатия), или же не проработано, как имеющее слишком много вариаций, из которых «не все йогурты одинаково полезны». К счастью, статья предназначена для «песочницы», поэтому я могу спокойно высказать собственные соображения — прежде, чем она отнимет чьё-то внимание, она должна получить одобрение более осведомлённых специалистов. Проблема нейросетей, обучаемых передавать изображение через «бутылочное горлышко», свойственна и естественным нейросетям. Вместе предаться лукавым мудрствованиямhttps://habr.com/ru/post/713790/?utm_source=habrahabr&utm_medium=rss&utm_campaign=713790
[Перевод] Создание проходимой червоточины с помощью квантового компьютераПонедельник, 30 Января 2023 г. 21:25 (ссылка)
Кротовые норы — морщинки на ткани пространственно-временного континуума, соединяющие два места, — кажутся чем-то из научной фантастики. Независимо от того, существуют они или нет, изучение этих гипотетических объектов может стать ключом в установлении связи между информацией и материей — загадкой, не дающей покоя физикам уже много лет. Читать дальше →https://habr.com/ru/post/713394/?utm_source=habrahabr&utm_medium=rss&utm_campaign=713394
[Перевод] Сравнение систем Machine Learning as a Service: Amazon, Microsoft Azure, Google Cloud AI, IBM WatsonПонедельник, 30 Января 2023 г. 14:16 (ссылка)
 Большинству компаний машинное обучение кажется чем-то сверхсложным, дорогим и требующим серьёзных специалистов. И если вы намереваетесь создавать новую систему рекомендаций Netflix, то так и есть. Однако тенденция превращения всего в сервис затронула и эту сложную сферу. Начать с нуля проект ML можно без особых инвестиций, и это будет правильным решением, если ваша компания новичок в data science и хочет начать с решения самых простых задач. Одна из самых вдохновляющих историй об ML — это рассказ о японском фермере, решившем автоматически сортировать огурцы, чтобы помочь своим родителям в этой утомительной работе. В отличие от крупных корпораций, этот парень не имел ни опыта в машинном обучении, ни большого бюджета. Однако ему удалось освоить TensorFlow и применить глубокое обучение для распознавания разных классов огурцов. Благодаря облачным сервисам машинного обучения вы можете начать создавать свои первые рабочие модели, делая ценные выводы из прогнозов даже при наличии небольшой команды. Мы уже говорили о стратегии машинного обучения. Теперь давайте рассмотрим лучшие на рынке платформы машинного обучения и поговорим об инфраструктурных решениях, которые нужно принять. Читать дальше → https://habr.com/ru/post/699436/?utm_source=habrahabr&utm_medium=rss&utm_campaign=699436
Цифровые флуктуации: почему ИИ ошибается и как с этим боротьсяПонедельник, 30 Января 2023 г. 13:02 (ссылка)
На базе нейронных сетей построены многочисленные системы искусственного интеллекта. Они считаются прогрессивным и достаточно надёжным инструментом анализа данных там, где задачу сложно формализовать. Им доверяют управление автомобилями и роботами, идентификацию людей, антифрод у банков и страховых компаний и другие ответственные задачи. При этом даже у лучших реализаций ИИ время от времени случаются грубые ошибки, возникновение которых бывает сложно объяснить. Специалист отдела перспективных исследований компании «Криптонит» Игорь Нетай предположил, что у разноплановых ошибок ИИ существует общая причина. Он выявил её в ходе модельного эксперимента с использованием более 50 000 сгенерированных нейронных сетей, обучение которых продолжалось в течение тысяч эпох для каждой из них. Скорее читать далее!https://habr.com/ru/post/713612/?utm_source=habrahabr&utm_medium=rss&utm_campaign=713612
[Перевод] Как структурировать процессы контроля качества для аннотаций медицинских снимковВоскресенье, 29 Января 2023 г. 20:33 (ссылка)
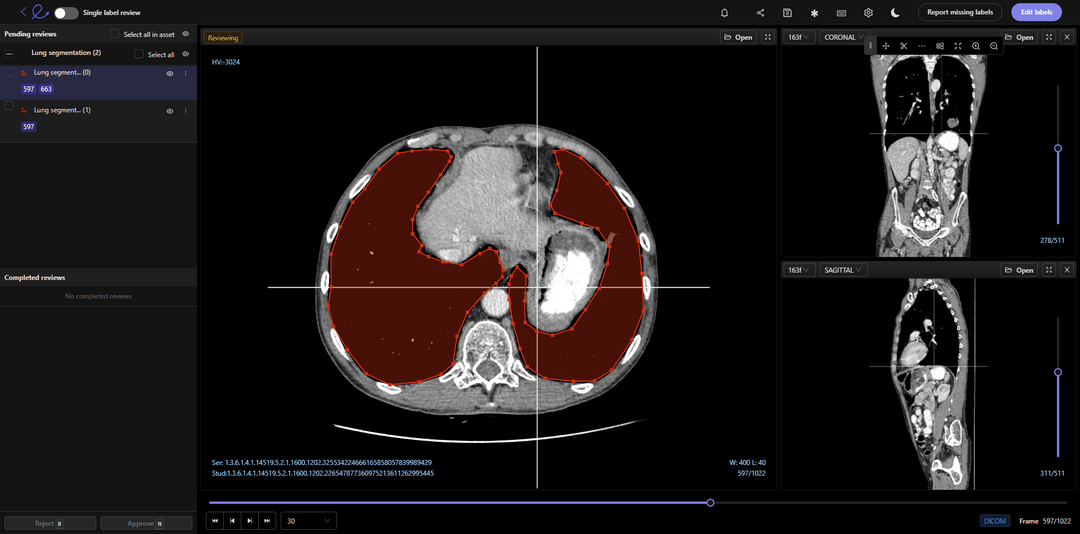 При создании любой модели компьютерного зрения командам разработчиков машинного обучения требуются высококачественные массивы данных с высококачественными аннотациями, чтобы обеспечить хорошую точность модели. Однако когда дело касается создания моделей искусственного интеллекта для применения в здравоохранении, ставки становятся ещё выше — эти модели могут непосредственно влиять на жизни людей. Их необходимо обучать на данных, аннотированных опытными медицинскими специалистами, у которых не очень много свободного времени. Также они должны удовлетворять высоким научным и нормативным стандартам, поэтому чтобы вывести модель из разработки в продакшен, командам разработчиков ML необходимо обучать их на лучших данных с лучшими аннотациями. Именно поэтому у любой компании, занимающейся компьютерным зрением (особенно если она создаёт модели для медицинской диагностики), должен существовать процесс контроля качества аннотаций медицинских данных. Читать дальше → https://habr.com/ru/post/705558/?utm_source=habrahabr&utm_medium=rss&utm_campaign=705558
Системы ИИ в p2p-формате: будущее ChatGPT, Midjourney, CopilotПятница, 27 Января 2023 г. 15:30 (ссылка)
https://habr.com/ru/post/713276/?utm_source=habrahabr&utm_medium=rss&utm_campaign=713276
|
|
|
LiveInternet.Ru |
Ссылки: на главную|почта|знакомства|одноклассники|фото|открытки|тесты|чат О проекте: помощь|контакты|разместить рекламу|версия для pda |