Расширяем экосистему Skyeng, открыв API словаря — первые участники конкурса |

Месяц назад мы открыли API нашего словаря, предложили всем желающим использовать его в своих приложениях и сервисах и даже объявили конкурс среди разработчиков. За прошедшее время мы получили 18 конкурсных заявок, среди них несколько готовых решений. Сегодня мы решили в своем блоге дать авторам четырех из них возможность рассказать о своем продукте (а мы прокомментируем).
Если вы пропустили пост о нашей экосистеме, где был объявлен конкурс – вот ссылка. На тот момент у нас еще не были готовы условия конкурса — вот и они. Призовой фонд нашего конкурса составляет 200 тысяч рублей — деньги для разработчика нового приложения или сервиса не бывают лишними!
Ну а теперь — к знакомству с первыми участниками.
 Lenny — это чатбот, который помогает пользователям пополнять их словарный запас по 10 слов в день. ЦА — это люди, которые изучают английский прямо сейчас или изучали его ранее. Большой словарный запас нужен для того, чтобы хорошо говорить, легко читать, понимать других и просто думать.
Lenny — это чатбот, который помогает пользователям пополнять их словарный запас по 10 слов в день. ЦА — это люди, которые изучают английский прямо сейчас или изучали его ранее. Большой словарный запас нужен для того, чтобы хорошо говорить, легко читать, понимать других и просто думать.
Чтобы слова не забывались, их нужно регулярно «освежать» в памяти. Далеко ходить мы не стали и построили алгоритм повторения на основе кривой забывания Эббингауза. На деле это значит, что пользователь повторяет слова через 30 минут, 1 день, 1 неделю, 1 месяц и 1 год. Таким образом слова закрепляются долговременной памяти. А в нужный момент их можно оттуда достать и применить.
Теперь о контенте. Перед началом конкурса у нас уже была база из 10 000 слов. И когда Skyeng предоставляет возможность сделать базу еще лучше, ей надо пользоваться. Мы так и сделали, получив и сохранив в отдельные файлы все необходимое.
А именно:
import requests
import time
from content import dictionary
def skyeng_word(word):
url = "http://dictionary.skyeng.ru/api/public/v1/words/search?_format=json&search={}".format(word)
response = requests.get(url)
try:
ids = response.json()[0]['meanings'][0]['id']
return skyeng_meaning(ids)
except:
return None
def skyeng_meaning(ids):
url = "http://dictionary.skyeng.ru/api/public/v1/meanings?_format=json&ids={}".format(ids)
response = requests.get(url)
return response.json()[0]['examples'][0]['text']
def get_example(word):
example = skyeng_word(word)
if example is not None:
return example
else:
return '!!! {} !!!'.format(word)
def add_example():
i = 1
while i <= 10000:
time.sleep(1)
example = get_example(dictionary[i]['word'])
with open('examples.py', 'a') as file:
file.write("{}: \"{}\"\n".format(i, example))
print(i)
i += 1
if __name__ == '__main__':
add_example()import requests
import time
from content import dictionary
def skyeng_word(word):
url = "http://dictionary.skyeng.ru/api/public/v1/words/search?_format=json&search={}".format(word)
response = requests.get(url)
try:
ids = response.json()[0]['meanings'][0]['id']
return skyeng_meaning(ids)
except:
return None
def skyeng_meaning(ids):
url = "http://dictionary.skyeng.ru/api/public/v1/meanings?_format=json&ids={}".format(ids)
response = requests.get(url)
return response.json()[0]['definition']['text']
def get_definition(word):
definition = skyeng_word(word)
if definition is not None:
return definition
else:
return '!!! {} !!!'.format(word)
def add_definition():
i = 1
while i <= 10000:
time.sleep(1)
definition = get_definition(dictionary[i]['word'])
with open('definitions.py', 'a') as file:
file.write("{}: \"{}\"\n".format(i, definition))
print(i)
i += 1
if __name__ == '__main__':
add_definition()import requests
import time
from content import dictionary
def skyeng_word(word):
url = "http://dictionary.skyeng.ru/api/public/v1/words/search?_format=json&search={}".format(word)
response = requests.get(url)
try:
voice_url = "http:{}".format(response.json()[0]['meanings'][0]['soundUrl'])
return requests.get(voice_url)
except:
return None
def get_voice():
i = 1
while i <= 10000:
time.sleep(1)
voice = skyeng_word(dictionary[i]['word'])
file_name = '{}.ogg'.format(i)
if voice is not None:
with open(file_name, 'wb') as file:
file.write(bytes(voice.content))
print(i)
i += 1
if __name__ == '__main__':
get_voice()Далее мы просто обновили текущую базу всем сохраненным.
Думаю, не стоит объяснять, почему мы сохранили контент у себя вместо того, чтобы каждый раз обращаться к API. Такой способ быстрее. А чем быстрее работает бот, тем довольнее пользователи.
Закончить свой дебют на Хабре хотелось бы афоризмом. Он отражает философию нашей небольшой команды — «Words can inspire and words can destroy. They are important to learn».
Благодарим школу Skyeng за возможность сделать продукт лучше. Спасибо всем, удачи!
Skyeng: Нам очень нравится бот LennyEnglishBot, он минималистичный и ненавязчивый, а работает на трех платформах – Telegram, Facebook и Viber. Для тех, кто не хочет или не может ставить лишнее приложение в телефон – самое оно, порог вхождения минимальный. В нашей экосистеме такой продукт очень был нужен.
Проблема, однако, в том, что этот бот не до конца интегрирован в нашу экосистему. Автор загнал туда фиксированный набор из 10 тысяч слов и подтянул к этому набору наши определения. Нет возможности тренировать произвольные слова и, главное для нас, нет возможности тренировать слова, взятые на изучение в Vimbox. Надеемся, что в будущих версиях бота все это будет учтено, потому что, повторимся, он нам очень-очень нравится.
readore — это коллекция книг, синхронизированных с аудио-дорожкой. Каждой книге присвоен уровень сложности, что позволяет легко подобрать литературу для своего уровня владения языком. При чтении можно мгновенно переводить незнакомые слова и добавлять в список слов для запоминания. Начиная с этого момента во всех книгах это слово будет выделено, а в течение дня мы будем отправлять ему уведомление "слово-перевод".

Приложение было реализовано еще до конкурса, когда для изучения испанского я купил Маркеса в бумажном переплете. Тогда и пришла идея изучать иностранный язык с любимыми книгами.
С помощью API SkyEng наше приложение теперь снова будет работать в Украине (до этого мы использовали Яндекс.Словарь), я как раз искал бесплатную альтернативу. Ну и теперь по многочисленным просьбам пользователей, readore может похвастаться offline-словарем.
Skyeng: Нам это приложение понравилось. Симпатичное, похоже на Bookmate. В некоторых книжках есть встроенная озвучка. Встроен словарь и переводчик, можно отмечать слова на изучение. И самое приятное, что в ближайшее время у учеников нашей школы появится возможность добавлять слова на изучение в нашем мобильном приложении Words.
Изучаю английский уже года три, до этого мечтал смотреть фильмы и читать литературу в оригинале. Мечта сбылась, но запоминание новых слов дается с трудом, постоянно попадаются слова, которые я не знаю.
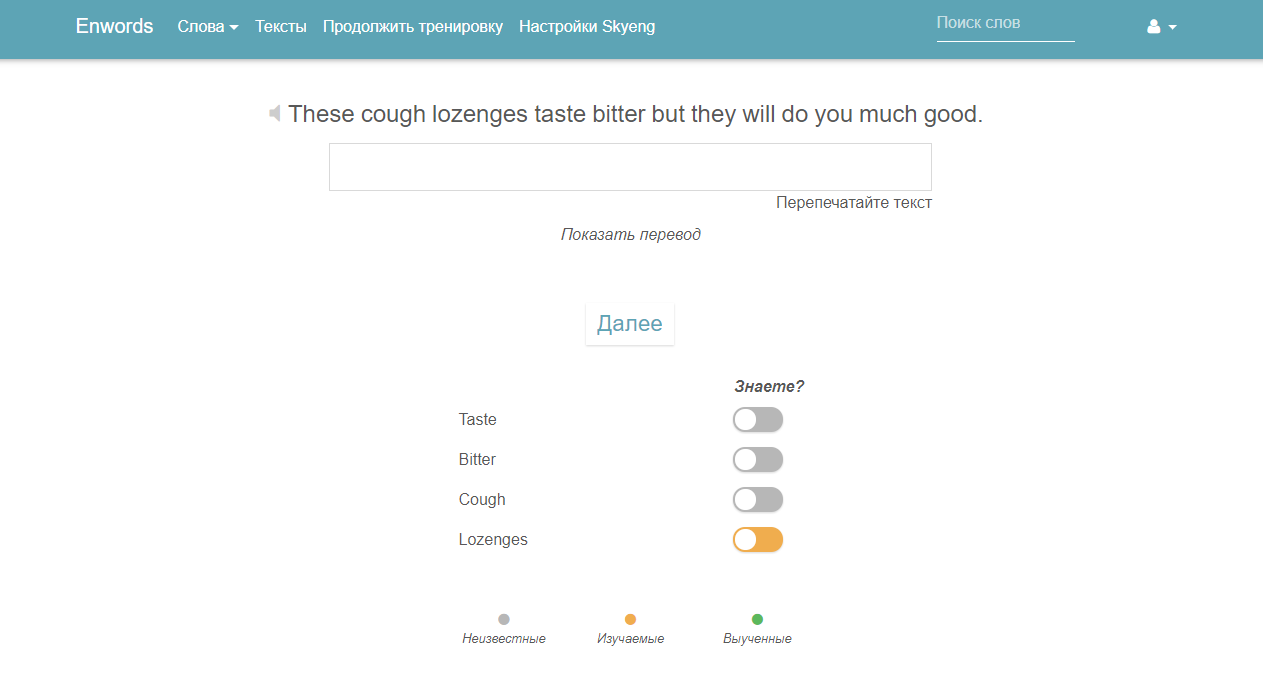
Прочитал когда-то статью на geektimes, из которой узнал про сайт tatoeba.org. Выгрузил оттуда список предложений, распарсил и выбрал самые часто встречающиеся слова, а дальше решил не ограничиваться только английским языком. В итоге была создана своя база, состоящая из 3.5 миллионов предложений, 500 тысяч слов на 30 языках, включая даже эсперанто. Создал web-приложение, в котором можно добавлять слова для изучения и отмечать выученные. Запоминание слов происходит при повторении их в небольших фразах.
Есть режим тренировок, где фразу нужно полностью перепечатать (заодно можно тренировать слепую печать). Можно загрузить текст для изучения, обычно использую тексты из уроков A.J. Hoge, он парсится, на выходе получается список слов, отсортированный по частоте встречаемости в этом тексте. Приложение не подойдет совсем новичкам в иностранных языках, грамматических уроков здесь нет.
Недавно подключил Skyeng API в связке с jQuery плагином qtip, теперь по клику на английское слово отправляется ajax запрос в Skyeng, и появляется перевод слова с озвучкой. Я давно хотел подключить такой функционал, руки не доходили, но со Skyeng это заняло буквально час. В ближайшее время позволю своим пользователям изучать слова, которые они добавили в учетной записи Skyeng, надеюсь это повысит конверсию.
Проект opensource, полностью бесплатный, если будет много пользователей, придется вводить платные функции, сервера нужно оплачивать, но основа все равно будет доступна для всех.
Написан на Ruby on Rails, любой желающий может предлагать свои идеи по функционалу, дизайну, маркетингу, вообще от product manager’а я бы не отказался.
Skyeng: Enwords предоставляет возможность самостоятельно составлять списки слов для изучения, это функционал, который активно просят пользователи нашего приложения Words. Однако текстовый парсер, в отличие от нашего Wordset Generator, не умеет сортировать слова по уровню сложности, поэтому на выходе получается очень большой список, начинающийся с артиклей, местоимений и заведомо всем известных слов; таким образом, надо потратить время на извлечение нужной для изучения лексики. Важная фишка Enwords – открытый исходный код.
UPD: новая важная фишка — возможность добавлять слова из своего аккаунта в Skyeng, достаточно указать e-mail в поле "Настройки Skyeng". Отлично!
 Идея приложения следующая: создать онлайн переводчик слов (фраз) с сохранением вариантов перевода (оффлайн) для детального изучения полученных значений. Т.е. подразумевается "бессистемное" расширение словарного запаса.
Идея приложения следующая: создать онлайн переводчик слов (фраз) с сохранением вариантов перевода (оффлайн) для детального изучения полученных значений. Т.е. подразумевается "бессистемное" расширение словарного запаса.
API Skyeng в настоящий момент используется в виде реализации запроса (метод "search": dictionary.skyeng.ru/api/public/v1/words/search). Порадовало то, что работает без авторизации, а результаты предоставляются как для русских, так и английских слов. Из структуры результатов запроса возникла простая реализация приложения в виде двух фрагментов: «список полученных (по запросу) слов» и «отображение значений (вариантов перевода)». Полученные значения отображаются в виде «визуальных карточек» с возможностью загрузки аудио-файлов для воспроизведения транскрипции. Результаты поискового запроса сохраняются в БД приложения (состоит из двух связанных таблиц, используется ORM Lite), аудио-файлы и изображения хранятся в директории приложения.
Каждому слову (результаты запроса) назначается одна из категорий:
1) "Для изучения",
2) "Изученное",
3) "Избранное",
4) "Просмотренное" (назначается при выборе слова для просмотра значений перевода);
при перемещении в "Изученное" формируется тестовое задание: выбрать верный из пяти предложенных вариантов перевода, случайная выборка из таблицы "значения" при совпадении поля "часть речи" (Part of speech).
Skyeng: «Больше Слов» — по сути упрощенный аналог нашего приложения Words. Хотя он не очень вписывается в нашу экосистему, мы рады его существованию: мы за разнообразие и возможность выбора.
Конкурс Skeyng продолжается, мы надеемся увидеть еще больше интересных разработок, использующих наш API. Если у вас есть идея или готовое приложение — заполните заявку.
Ну а если вы хотите разрабатывать приложения внутри Skyeng — у нас, как всегда, есть интересные вакансии.
| Комментировать | « Пред. запись — К дневнику — След. запись » | Страницы: [1] [Новые] |






